

OK, ik weet het: de titel van deze blog klinkt niet sexy. Het liefst zijn we als (SAP) BI Consultants vandaag de dag bezig met onze nieuwste speeltjes: Native HANA (liefst 2.0), SAP Analytics Cloud en wellicht zelfs SAP Data Warehouse Cloud. Aan de andere kant zijn er meer dan voldoende organisaties die nog prima uit de voeten kunnen met “traditioneel” Datawarehousing in SAP BW (hopelijk wel op SAP HANA). Bovendien heb ik in een eerdere blog al aangegeven dat een allesomvattende DWH suite als SAP BW niet te vergelijken is met het volledig zelf opbouwen van een Datawarehouse in een Native omgeving zoals bijv. SAP HANA.
Hybride oplossingen
Het mooie is echter dat in lang niet alle gevallen een keuze gemaakt hoeft te worden. Op tal van gebieden zijn hybride oplossingen denkbaar waar het beste uit twee werelden wordt gehaald: de robuustheid van SAP BW en de agility van SAP HANA. Een mooi voorbeeld van het samengaan van beide werelden is de vastlegging van data in een BW ADSO in combinatie met een HANA Calculation View die de ETL logic voor zijn rekening neemt. Allemaal niets nieuws onder de zon en ook zeker geen rocket science. Toch ben ik er erg enthousiast over en verbaas me dat er niet veel meer over wordt geschreven. Ook bij de collega’s in het netwerk zit dit nog maar beperkt in de gereedschapskist.
Transformation Logic
Als we uitgaan van het opnemen van de transformation logic binnen de DWH omgeving (dus zonder aanvullende ETL tools) hebben we in SAP BW grofweg de volgende opties:
- Formula’s: de standaard out-of-the box tool die door SAP standaard in BW is ingebouwd. De mogelijkheden hier zijn beperkt maar worden ook nog steeds onderschat waardoor er al snel wordt teruggevallen op een (ABAP) routine. Formula’s hebben het grote voordeel dat ze zijn mee-geëvolueerd met HANA en op DB Level worden uitgevoerd: razendsnel en optimaal gebruikmakend van de voordelen van HANA. Let uiteraard wel weer op het gebruik van Custom made formula’s waarbij gebruik is gemaakt van ABAP. Al vanaf 1 regel ABAP zal de transformation worden uitgevoerd op Applicatie Level en dus onnodige data verplaatsing tussen DB en Applicatie.
- Routines: hier kan de ware programmeur helemaal los gaan met Start-, Eind- en Regelroutines en deze voorzien van de meest complexe logica. En dan maar hopen dat de Developer bij een BW systeem met HANA als onderliggende DB uiteraard kiest voor de AMDP en niet meer voor ABAP. Ook met een ABAP routine wordt immers geen gebruik gemaakt van de unieke eigenschap van HANA: de processing laten uitvoeren op DB Level.
- HANA Calculation Views: de betrekkelijk “nieuwe” toevoeging aan ons ETL instrumentarium en het centrale onderwerp van deze blog. Ook de HANA Calculation View (vanaf nu in deze blog genoemd: HANA CV) kan de volledige ETL Logic verzorgen. En geloof me: je moet wel iets heel exotisch bedenken, wil je het niet kunnen oplossen met een HANA CV. Daar komt bij dat de agility van een HANA CV hoog is en de opzet uiterst transparant, wat ten goede komt aan de onderhoudbaarheid. Ook niet onbelangrijk: de HANA CV wordt – uiteraard – altijd uitgevoerd op DB Level en er wordt dus optimaal gebruik gemaakt van HANA als processing engine.
HANA CV als BW DataSource: hoe doe je dat?
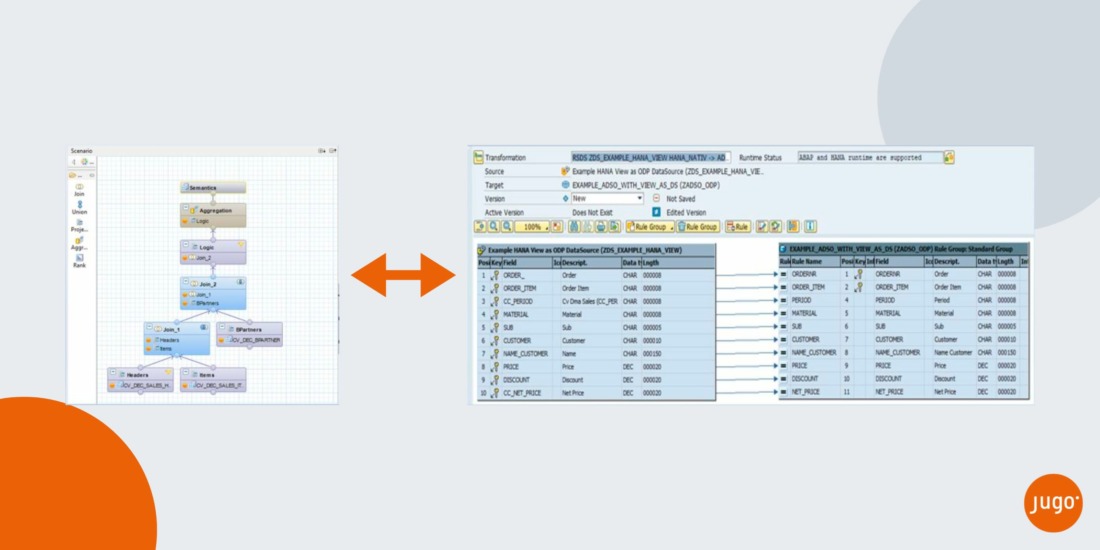
Onderstaand laat ik in zes stappen zien hoe eenvoudig het is om een HANA CV te gebruiken als DataSource voor SAP BW. Vervolgens brengen we daar alle noodzakelijke transformation logic in onder. Voorwaarde is wel dat het HANA systeem als ODP Bronsysteem is gedefinieerd in SAP BW.
Stap 1: creëer HANA CV
- Creëer de HANA CV. De wijze waarop je dit doet wordt als bekend verondersteld.
- Het gebruik van de HANA CV als DataSource voor BW legt geen enkele beperking op. Je kunt dan ook van alle beschikbare functionaliteit gebruik maken om de gewenste ETL logica in te vullen (Joins, Unions, Calculated Columns, Table Functions etc.).
- Merk op dat in dit voorbeeld ook gebruik is gemaakt van een Input Parameter. Een heel prettige feature waar ik later nog op terug zal komen.
- Controleer uiteraard of de CV de gewenste output geeft.
Stap 2: creëer ADSO
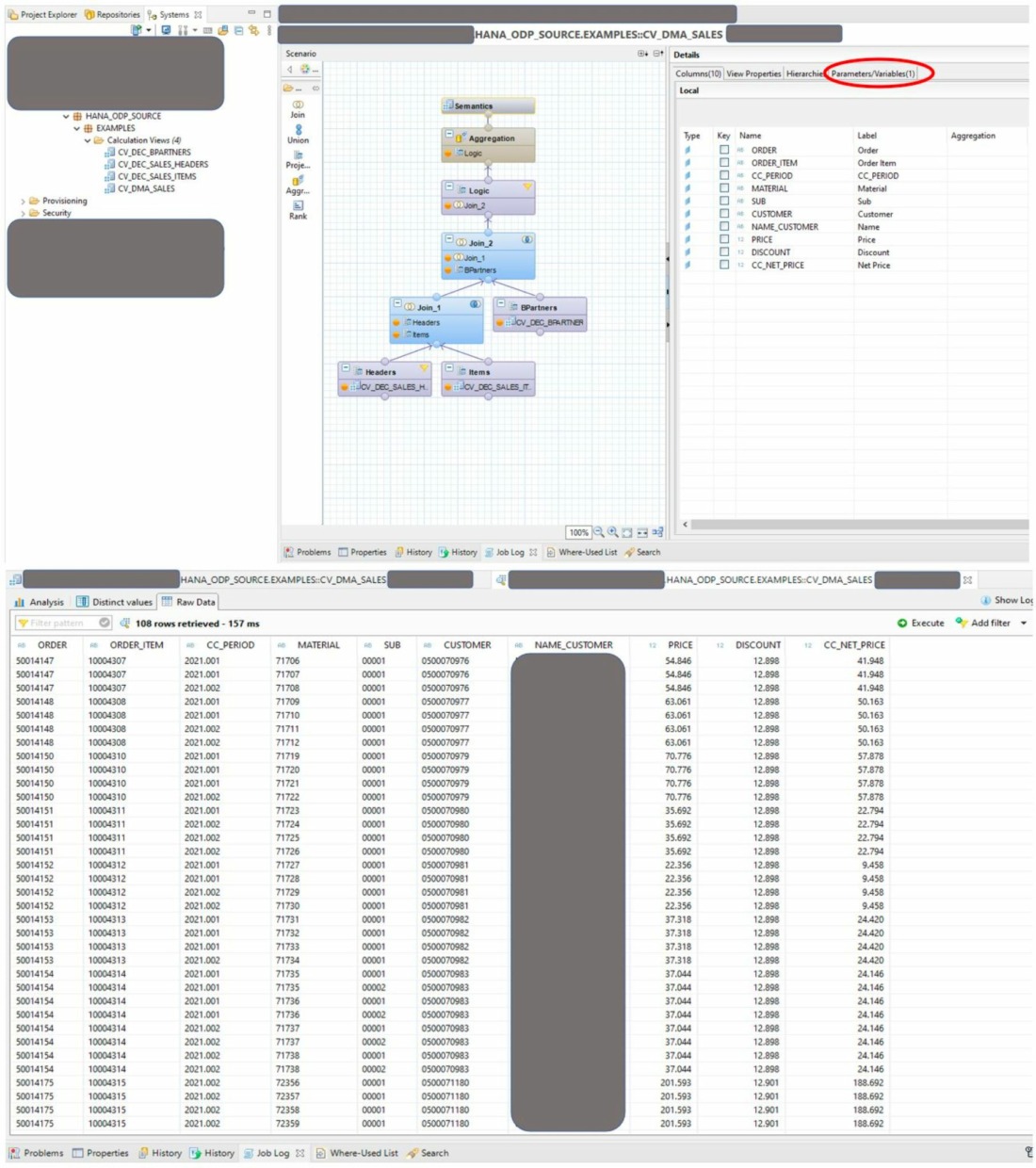
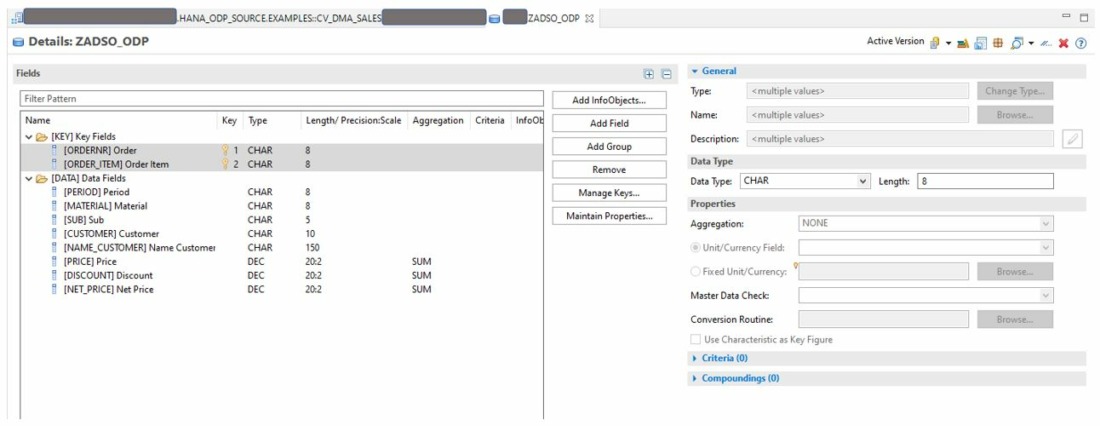
- Het scenario in deze blog gaat er van uit dat we de agility van de HANA CV combineren met de robuustheid van SAP BW voor de data opslag in een Advanced Data Store Object (ADSO dus).
- Creëer en activeer de ADSO zoals bijv. in de figuur is weergegeven.
Stap 3: HANA CV als DataSource
We gaan nu de verbinding maken tussen de HANA CV en SAP BW door de HANA CV te “promoveren” tot BW DataSource. Het zal de leeftijd, gewoonte of simpelweg voorkeur zijn (of misschien ook niet) maar waar het kan geef ik nog steeds de voorkeur aan onze vertrouwde SAP GUI. Die zie je daarom ook in de volgende afbeeldingen verschijnen maar uiteraard kan dit alles ook worden gedaan in Eclipse of de (toekomstige) Web Tools.Creëer en activeer de ADSO zoals bijv. in de figuur is weergegeven.
- Creëer onder Datasources een nieuwe DS. Geeft de DS een naam en verwijs naar het ODP HANA Source System.
- Vervolgens koppel je de DS aan de eerder gemaakte HANA CV en dat is wel even een “dingetje” waar SAP niet zo goed over heeft nagedacht.
- Klik op het “hierarchy” knopje.
- Zoals we gewend waren bij de (voor velen inmiddels prehistorische) BEx Queries blijken de HANA CV’s naast een logische naam (in dit geval: CV_DMA_SALES) ook een technische GUID te hebben. En laten we die laatste nu net nodig hebben om de koppeling aan te brengen tussen DS en HANA CV. Er zal ongetwijfeld ergens een tabel zijn waar de link is gelegd tussen de logische naam en de technische GUID maar die heb ik helaas nog niet kunnen vinden (reageer aub als je die wel hebt gevonden).
- We zullen dus de juiste HANA CV moeten zien te vinden en daar hebben de SAP ontwikkelaars ons niet echt geholpen: het zoekschermpje is veel te klein en kan niet groter worden gemaakt, de logische viewnaam wordt afgekapt en zoals gezegd kennen we de relatie tussen logische en technische naam niet.
- Mijn methode: kies de bovenste view in het package waar je je HANA CV hebt ondergebracht en bekijk welke velden dit oplevert in de DataSource. Zijn dit de velden die je verwacht? Bofkont!! Zo niet: opnieuw beginnen en de volgende HANA CV proberen.
- Heb je uiteindelijk de juiste view gevonden maak dan in Excel een vertaaltabel met logische en technische naam. Bewaak die met je leven!
- Merk op dat in het eerste veld van de DataSource een veld is meegekomen met een technische sleutel als Field Name. Dat is de Input Parameter “PERIOD” uit de HANA CV en is super fijn om te hebben.
Stap 4: De Transformation
- Het is nu tijd om de DataSource met de HANA CV als bron te koppelen aan de ADSO. Dat doe je met het bekende BW Transformation object.
- Creëer vanuit de ADSO de Transformation en geef de zojuist gecreëerde ODP DataSource aan als Source object.
- Hoewel je de Transformation Logic hebt opgenomen in de HANA CV heb je de BW Transformation technisch wel nodig voor de koppeling tussen DS en ADSO.
- Alle koppelingen zijn hier gewoon 1:1.
- Uiteraard kun je in de Transformation ook weer aanvullende logica opnemen maar dat zou ik sterk afraden. In dat geval heb je de Tranformation Logic namelijk op 2 plekken: in de HANA CV én in de BW Transformation. Dat is voor de overzichtelijkheid en de onderhoudbaarheid niet slim. Bovendien: ik daag je uit logica te bedenken die je wel in een BW Transformation zou kunnen opnemen en niet in een HANA CV. Niet doen dus!
Stap 5: Data Transfer Process
We zijn bijna klaar voor de dataload. Nog even de afsluitende DTP creëren:
- Creëer op de gebruikelijke manier de DTP.
- In dit geval is de gecreëerde ADSO weer het Target object en de DataSource gekoppeld aan de HANA CV het Source object.
- Kies voor de optie “FULL” als Extraction Mode. Een HANA CV kent geen Delta Capabilities, tenzij je daar zelf iets slims voor bedenkt in je HANA CV (een “pseudo delta” oid).
- Kies voor de optie “Directly from source system, PSA not used” als Data Extraction mode.
- Negeer een eventuele foutmelding (“Extraction directly from DataSource not supported”).
- Merk op dat de Input Parameter die is gedefinieerd in de HANA CV netjes beschikbaar is in het filter van de DTP.
- Geef de parameter een waarde indien gewenst of wanneer de Input Parameter in de CV mandatory is gemaakt.
Stap 6: De Dataload
- Start de DTP en zie hoe de data netjes en bliksemsnel in de ADSO wordt geladen.
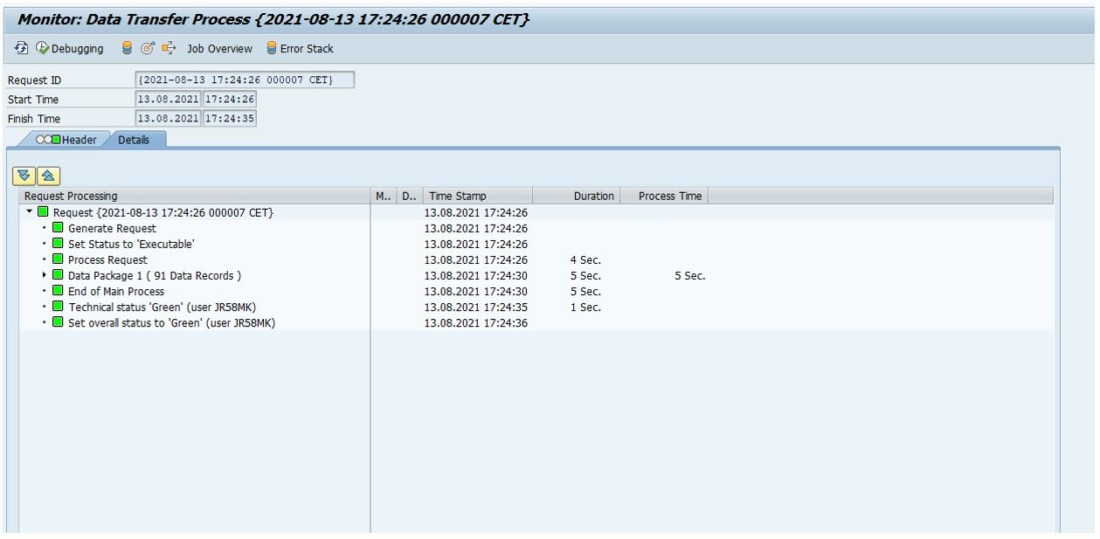
Mocht je hierna nog wijzigingen willen aanbrengen in de HANA CV dan kan dat uiteraard altijd. Let wel op dat ook hier de HANA CV zich gedraagt als een “normale” BW DataSource en zal je dus een replicatie moeten uitvoeren om beide kanten weer in sync te brengen.
Voilà, je hebt het beste uit 2 werelden gehaald met een hybride oplossing tussen Native HANA en SAP BW. Zoals eerder aangegeven ben ik erg enthousiast over dit stukje gereedschap dat we kunnen toevoegen aan onze uitgebreide set met beschikbare tools. Maar elke situatie en elke requirement is weer anders. Het is nu aan jou of het toepasbaar is in jouw specifieke situatie.

BI Consultant
Henk van der Haar
Wil je meer informatie?
Neem contact op en kom in gesprek met onze experts.
