

Een discussie brak los
De stof van deze verhitte discussies is inmiddels weer wat neergedaald en ook SAP heeft het antwoord op deze vragen laten zien. Konden we bij BW on HANA de leverancier nog verdenken van het zoethouden van bestaande klanten, met de recente lancering van BW/4HANA is het wel duidelijk dat SAP vooralsnog blijft geloven in een specifieke toolset voor (Enterprise) Data Warehousing. Natuurlijk herkennen we in BW/4HANA het oude vertrouwde BW maar zowel zichtbaar als niet-zichtbaar is er door SAP flink geïnvesteerd in dit nieuwe product.
Persoonlijk heb ik de discussie indertijd met verbazing gevolgd. Is het wel reëel een alles omvattend EDW platform als BW te vergelijken met wat in feite niets meer of minder is dan een database? Ik weet het: vloeken in de (SAP) kerk. HANA is meer dan een (column based) database en is in feite een ontwikkelplatform waarvan de database slechts onderdeel uitmaakt. In het kader van deze blog beperk ik me echter tot de database service van HANA. De keuze voor BW of Native HANA moet natuurlijk altijd in de context van de situatie worden gezien. Een betrekkelijk kleine organisatie die alleen ECC of S/4HANA heeft draaien is natuurlijk niet te vergelijken met een grote (internationale) organisatie die geografisch sterk gespreid is, te maken heeft met tal van bronsystemen met niet-geharmoniseerde data maar met wel behoefte aan geconsolideerde rapportages. Daarnaast is BW een volledige toolset met tal van embedded functies voor development en beheer van het (E)DW terwijl in Native HANA het nodige zal moeten worden gebouwd door de ontwikkelaar of simpelweg afwezig is.
BW vs Native HANA
Laten we eens een voorbeeld nemen: de CompositeProvider. De BW-er kan zich hier grotendeels richten op de functionele modelering van het object en hoeft zich niet te bekommeren wat er onder de motorkap allemaal gebeurt in de zin van fysieke HANA objecten. En geloof me: een blik op de gegenereerde HANA Calculation View leidt al snel tot de conclusie dat dit toch wel een erg efficiënte wijze van ontwikkelen is. En laten we nog eens stil staan bij het elementaire deeltje van BW: het InfoObject. De functionaliteit die dit object levert (attributen, teksten, tijdafhankelijkheid, taalafhankelijkheid, herbruikbaarheid, hiërarchieën etc.) is echt fantastisch. Ik daag de enthousiaste Native HANA modeler graag uit om dit na te maken. Gaat ongetwijfeld lukken want BW kan het onder water blijkbaar ook genereren maar dat zal toch “iets” meer inspanning kosten.
Modeling in Native HANA
Goed, de discussie BW vs Native HANA hebben we nu dus wel gehad. Het zal duidelijk zijn dat beide scenario’s voor het inrichten van een (E)DW elkaar niet bijten of uitsluiten maar afhankelijk zijn van de specifieke situatie en mogelijk zelfs complementair kunnen zijn. Ik zal hier verder niet ingaan op de te maken afwegingen bij de keuze voor BW of Native HANA maar kom tot de kern van deze blog: als de keuze dan is gevallen op Native HANA, welke spelregels moeten we daar dan hanteren? In de BW wereld zijn we dankzij Juergen Haupt vertrouwd geraakt met de Layered Scalable Architecture (LSA), later – door de komst van HANA – gevolgd door de LSA++. Het volgen van de LSA principes leidt tot een geharmoniseerd, consistent (E)DW en voorkomt de gehate “Stove Pipes”. Met het gebruik van Native HANA voor de inrichting van het DWH lijkt de discussie wat betreft dit aspect weer terug bij af te zijn. Voor je het weet wordt er weer wat af “gejoint” richting de specifieke vraag en is de consistentie weer ver te zoeken. Deels is dit ook te wijten aan het ontbreken van specifieke DWH functionaliteit in Native HANA die we in BW wel terug vinden. Denk bijvoorbeeld aan de dimensies (HANA: “Attributes”) die we in BW definiëren in geharmoniseerde en herbruikbare InfoObjecten. Native HANA kent dergelijke functionaliteit logischerwijs niet en dan komt het aan op spelregels en de kennis / kunde van de ontwikkelaar.
LSA in Native HANA
Het kopje van deze paragraaf pretendeert nogal wat. Het is zeker niet de bedoeling mijn eerste rudimentaire gedachtenspinsels te vergelijken met het gedachtegoed van Juergen Haupt. Wel hoop ik hiermee de discussie op gang te brengen welke spelregels we zouden moeten hanteren om te komen tot een goede inrichting van het DWH nadat de keuze is gevallen op Native HANA. Hoe voorkomen we dat we in dezelfde valkuil trappen die we ook bij BW hebben gezien met (heel) veel rework tot gevolg? Kunnen populaire modeleringstechnieken als Data Vault mogelijk een bijdrage leveren?
Onderstaand geef ik mijn visie op dit vraagstuk in een eerste praktische uitwerking van wat ik ook maar heb genoemd een “Layered Structure in Native HANA”. In onderstaand schema de mogelijke Layers in een (logisch) DWH in Native HANA. Een belangrijk verschil tov de meeste implementaties in BW is de aanwezigheid van slechts één persistente data laag. Alle daaropvolgende logica is volledig gemodelleerd in opeenvolgende (“stacked”) HANA Calculation Views.
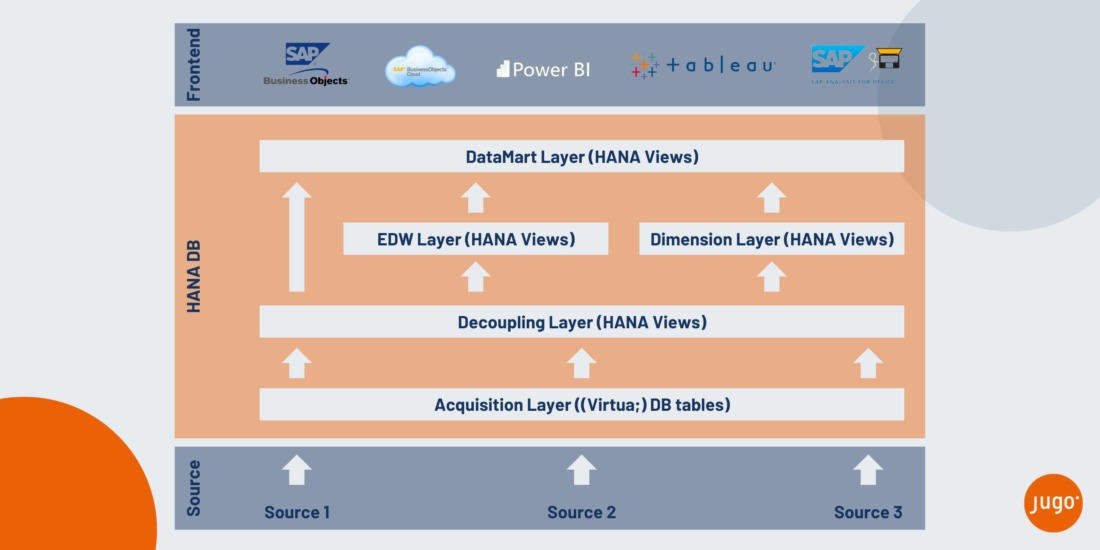
Toelichting op de Layers:
- Source Layer
Betreft de data aanleverende bronsystemen. Wijze van aanleveren kan variëren (directe / scheduled replicatie, HCI, SDI, Flat-File, met / zonder tussenliggende ETL tooling zoals bijv. BODS. - Acquisition Layer
Deze Layer vormt de enige persistente opslag van de data afkomstig uit de bronsystemen en bestaat uit fysieke en / of virtuele Database tabellen. In geval van virtuele tabellen wordt de data niet fysiek gerepliceerd maar wordt de data “at-runtime” opgehaald uit het bronsysteem. - Decoupling Layer
De Decoupling Layer vormt het ontkoppelvlak tussen fysieke data – afkomstig van de bronsystemen – en het virtuele DWH. De Decoupling Layer wordt gemodelleerd middels HANA Calculation Views waarbij elke (virtuele) DB tabel in de Acquisition Layer 1:1 is gekoppeld aan een HANA Calculation View in de Decoupling Layer. Slechts technische transformaties (bijv. verschil in technische velddefinitie) zijn toegestaan. In beginsel wordt alle data uit een (virtuele) DB tabel in de Acquisition Layer overgenomen in de HANA Calculation Views in de Decoupling Layer. De Decoupling Layer leent zich bij uitstek voor rapportage over ruwe, onbewerkte brondata. - EDW Layer
De Enterprise Data Warehouse Layer (EDW) vormt het hart van het DWH en vormt daarmee de bekende “Single Version of the Truth” van de organisatie. In de EDW Layer wordt de data omgevormd tot “Business entiteiten”. Tussen de HANA Calculation Views in de Decoupling Layer en de EDW Layer bestaat een N:M relatie. Met behulp van transformation logic in de HANA Calculation Views wordt in de EDW Layer generieke Business Logica toegevoegd. De labels voor Measures en Attributes worden in de Semantics van de views geharmoniseerd tot conforme dimensies. De EDW Layer wordt ook gebruikt voor Data Cleansing en -harmonisatie. Slechts voor Reporting relevante data wordt overgenomen van de Decoupling Layer naar de EDW Layer. - Dimension Layer
De Dimension Layer is bestemd voor de afbeelding van Teksten en Masterdata van Conforme Dimensies. Ook in de Dimension Layer wordt generieke Business Logica toegevoegd en zijn de labels voor Attributes in de Semantics van de HANA Calculation Views geharmoniseerd tot conforme dimensies. Tijd- en taalafhankelijkheid worden in de Dimension Layer gemodelleerd, evenals hiërarchieën.Een bijzondere vorm van een dimensie is de Time Dimension. Deze dimensie – eveneens gemodelleerd als HANA Calculation View – zorgt er voor dat datumvelden in de transactionele data kunnen worden geaggregeerd naar week, maand, fiscale periode, jaar etc.De Dimension Layer is nog het meest te vergelijken met de herbruikbare InfoObjecten die we kennen uit BW. Een dergelijk mechanisme kent Native HANA echter niet en zal daarom een grote mate van discipline vergen en een (externe) data dictionary.
- DataMart Layer
De DataMart Layer vormt het ontkoppelpunt van het DWH naar de buitenwereld (Front-End tools, API’s e.d.) waarmee de data wordt geconsumeerd / gepresenteerd. Alléén HANA Calculation Views uit de DataMart Layer worden beschikbaar gesteld aan de Front-End tools. Een HANA Calculation View in de DataMart Layer beschrijft de data die is bestemd ter ondersteuning van een specifieke vraag, proces of doelgroep. De bron van de HANA Calculation View in de DataMart Layer zal over het algemeen bestaan uit 1 of meer Calculation Views uit de EDW Layer aangevuld met Calculation Views uit de Dimension Layer die veelal middels een “starjoin” aan elkaar worden gekoppeld. Het is toegestaan specifieke Business Logica aan de view toe te voegen als de requirements daarom vragen. - Front-End Layer
Deze Layer bevindt zich buiten het DWH en bestaat uit tooling die de HANA Calclulation Views uit de DataMart Layer consumeren en de data presenteren.
Mijn Conclusie
Afhankelijk van de specifieke situatie kan Native HANA een prima alternatief en / of aanvulling zijn op SAP BW voor de inrichting van een (logisch) DWH. Release op release wordt de beschikbare functionaliteit verbeterd en uitgebreid. Bovendien kan met Native HANA optimaal gebruik worden gemaakt van het Code-to-Data paradigma. De openheid en flexibiliteit van HANA zou er echter niet toe moeten leiden dat we in dezelfde valkuil trappen als in het verleden regelmatig is gedaan bij SAP BW implementaties. Conforme dimensies, herbruikbarheid van objecten, beheersbaarheid en een heldere structuur van (virtuele) Layers in het DWH blijven net zoals in BW van groot belang. We zouden lering moeten trekken van gemaakte fouten in het verleden. Ik hoop met deze blog daartoe een aanzet te hebben gegeven.

BI Consultant
Henk van der Haar
Wil je meer informatie?
Neem contact op en kom in gesprek met onze experts.
